함수형 사고와 Ramda.js로 기업 데이터 처리하기
데이터를 함수의 연결로 처리하는 함수형 프로그래밍 관점을 공부하고 실무에 적용한 사례를 적었습니다.
들어가며: 이론과 실전의 괴리
오늘은 함수형 프로그래밍에 대해 얘기해볼까 한다. ‘이론과 실전의 괴리’라는 소제목을 붙인 이유는 함수형 프로그래밍이 글쓴이 같은 선량한 주니어에게 ‘뭐든지 가능하게 해 주는, 당신을 좀 더 스마트하게 만들어 줄’ 등등의 수식어를 달고 여러 인터넷 강의로 등장하는 모습을 보며 ‘와 뭔가 멋있어 보여! 당장 배워야지’라는 생각을 들게 했기 때문이다. 그렇게 여러 강의를 전전했고… 새로운 개념을 배운 것 자체는 좋은 일이었지만 뭔가 광고성 멘트에 비해서는 괴리가 있다는 느낌이 들었다.
함수형 프로그래밍이냐 객체지향 프로그래밍이냐 하는 논란이 지금도 있는진 모르겠지만, 글쓴이의 경우 필요한 영역마다 섞어 쓰면 좋다는 애매모호한 대답을 할 것 같다. 객체지향 설계가 관리해야 하는 상태를 객체 안에 밀어 넣어 캡슐화시키는 전략을 쓴다면, 함수형 설계는 아예 상태를 최소화하거나 없애는 방향으로 나아간다. 두 전략의 차이로 인해 강점을 발휘하는 영역도 달라진다. 함수형 설계는 큰 규모의 데이터를 여러 단계에 걸쳐 가공하는 등 어떤 프로그램의 ‘재료’를 다루는 일에 강하다. 반면 객체지향 설계는 바로 그 데이터가 위치해야 할 장소를 구획해주는 일, 어디에서 어디로 흘러가야 하는지 ‘구조’를 세우는 일에 강하다. 오랜 세월 쌓여 온 수많은 종류의 디자인 패턴이 검증된 구조인 셈이다.

Photo by Meta Zahren on Unsplash
또 다른 불만 중의 하나는(내 돈!) 대부분의 함수형 프로그래밍 강의가 특정한 툴 사용법으로 귀결된다는 것이었다. 나는 좀더 이론적인 영역을 배우고 싶었는데, 강의들은 곧장 어떤 개념을 실습하는 모습을 보여주려고 하다 보니 그랬던 모양이다.
이런 내게 많은 도움이 된 책이 있었다. <함수형 사고>라는 책이었다.
 | 함수형 사고 -  닐 포드 지음, 김재완 옮김/한빛미디어 |
<함수형 사고>는 함수형 프로그래밍이 무엇이며 왜 이러한 접근법이 생겨났는지, 핵심 함수는 무엇인지를 중점적으로 설명해주려고 한다. 그 점이 읽기 좋았다. 책 전반에 걸쳐 쓰는 코드는 자바로 되어 있다. 그러나 금방 알아채겠지만, 클로저 언어를 너무 좋아하는 필자가 자바 유저들에게 언어 홍보를 하려는 건가 (…) 싶은 기분이 들 정도로 클로저 예찬을 한다. 그러나 클로저를 어떻게 쓰면 되는지 가르쳐주려고 하는 것까진 아니고 함수형 사고방식이 언어적으로 구현된 예를 보여줄 때만 클로저 덕질을 하신다… 라고 생각하면 될 것 같다.
이 책을 읽던 중에 사내에서 기업 데이터를 가공하여 포트폴리오를 구성해 보여주는 페이지를 개발해야 했다. (데이터가 어떤 출처를 지녔는지 등등 자세한 내용은 보안 문제로 말할 수는 없지만) 제법 큰 규모의 데이터였고, 재무정보를 담은 필드는 JSON의 key조차 일련번호와 코드로 되어 있어 알아보기도 어려웠다. 거기다 하나의 array에 각 해당 연도에 해당하는 재무 데이터가 순서가 보장되지 않은 채로 담겨 있기도 했다. 데이터 식별 - 정렬 - 추출 및 가공까지를 빠르게 처리해야 하는 상황. 잘 해내기 위해서는 함수형 설계의 관점으로 흐름을 만들어야겠다는 생각이 들어 과감히 책을 구매했다. (책 덕후들은 이런 핑계로 책을 사기도 하지요)
필터, 맵, 폴드(리듀스)
고계함수 중에는 삼대장이라 불릴 만큼 대표적인 함수가 세 가지 있다. 필터, 맵, 리듀스인데 하나씩 살펴보기로 하자.
1. 필터
필터는 주어진 목록을 사용자가 정한 조건에 따라 더 작은 목록으로 만드는 작업이다. 예를 들어 주어진 숫자의 약수를 배열로 리턴하는 함수를 만든다고 하자.
const factorsOf = number =>
Array.from(new Array(number).keys()) // 0에서 number - 1 까지 연속되는 배열 생성
.map(x => x + 1) // 각 요소에 1씩 더하여 1 - number까지 연속되는 배열로 변경
.filter(x => number % x === 0); // number로 나누어 나머지가 0인 숫자 필터
factorsOf(6); // [1, 2, 3, 6];1에서 number까지 연속되는 배열을 생성한 뒤, number와 나누어 떨어지면 true를 반환하는 콜백 함수를 filter에 제공해 원하는 결과를 얻는다.
2. 맵
필터가 조건에 맞는 요소만 골라내 더 작은 목록을 만드는 일이라면, 맵은 요소에 변화를 적용한 새로운 목록을 만드는 작업이다.
const greeting = users => users.map(user => `Hello, ${user}!`);
gretting(['John', 'Mary', 'Tom', 'Susan']);
// ['Hello, John!', 'Hello, Mary!', 'Hello, Tom!', 'Hello, Susan!'];3. 폴드
폴드는 함수 연산으로 목록의 첫째 요소와 누산기 초기값을 결합하는 작업이다. 리듀스라고 부르기도 한다.
const addAll = nums => nums.reduce((acc, cur) => acc + cur);
addAll([1, 2, 3, 4]); // 10
/*
* + => 10
* / \
* + 4
* / \
* + 3
* / \
* 1 2
* // 초기값을 따로 지정하는 경우도 있고, 처음 더하는 값을 초기값으로 지정하는 경우도 있다.
*/위의 세 가지 고계함수들은 거의 모든 프로그래밍 언어에서 발견할 수 있다. 공통적으로 구현되어 있는 표준적인 함수를 이용해 문제를 해결하다 보면, 개발자는 자신이 해결해야 할 문제를 정량적으로 생각할 수 있게 되고 다른 개발자들과 쉽게 공유할 수 있는 형태로 문제를 재정의하게 된다.
클로저, 커링, 부분 적용
개발자가 관리하던 ‘상태’를 프로세스나 언어 자체적인 영역 안으로 숨기는 것이 함수형 사고의 목표인 만큼, 클로저, 커링, 부분 적용은 함수형 사고에서 반드시 알고 넘어가야 할 개념이다.
클로저
클로저(closure)란 내부 함수가 참조하는 외부 환경의 인자가 계속 기억되는 현상을 말한다. 자바스크립트 환경 안에서만 한정지어서 설명하자면, 내부함수 B가 실행될 경우 내부함수 B를 감싸고 있던 외부함수 A의 실행 컨텍스트가 종료된 이후에도 외부함수 A의 환경이 계속 호출 가능한 상태로 남는 것을 말한다.
// https://developer.mozilla.org/ko/docs/Web/JavaScript/Guide/Closures
function outer() {
const name = 'john';
function inner() {
console.log(`Hello, ${name}!`);
}
inner();
}
outer(); // Hello, john!실행 순서를 보면 outer() -> inner()로 진행되는 것을 알 수 있는데, inner()가 실행될 즈음이면 실행 컨텍스트에서 outer()가 종료되었을 텐데도 여전히 inner 함수는 스코프 체인 안에 name 변수를 기억하고 있다.
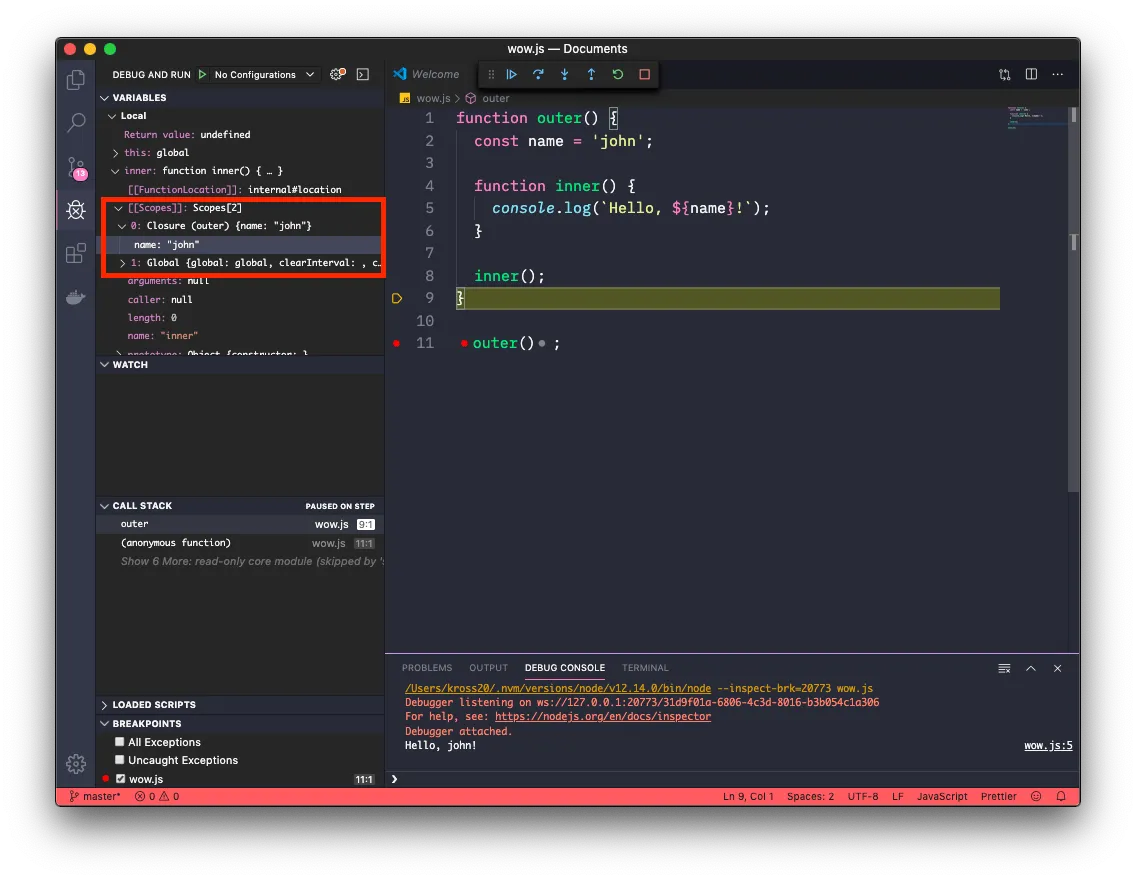
VSCode로 디버그 모드를 켜면 inner 함수의 스코프를 볼 수 있다.
클로저는 지연 실행(deferred execution)을 유도할 때 요긴하게 쓰인다. 여러 조건에서 재사용되는 함수를 만들고자 할 때, 외부 함수에 인자를 저장해두고 그 인자를 참조하는 내부 함수를 리턴하도록 만들 수 있다.
function makeEmployee(name) {
return {
getName() {
return name;
},
greeting() {
return `Hello, ${name}!`;
},
};
}
const john = makeEmployee('john');
const susan = makeEmployee('susan');
console.log(john.getName()); // john
console.log(john.greeting()); // Hello, john!
console.log(susan.getName()); // susan
console.log(susan.greeting()); // Hello, susan!참고: 객체에 비공개 멤버를 만드세요 - clean-code-javascript
이렇게 만들면 john, susan 변수는 언제든 원하는 순간에 이름과 인사말을 출력할 수 있도록 실행을 지연시킨 함수가 된다. 클로저는 각 변수가 고유하기 때문에 서로에게 영향을 미치지 않아 정보 은닉, 캡슐화 또한 가능하다.
커링
커링(currying)이란 인수가 여러 개인 함수를 인수 하나인 함수들의 체인으로 바꿔주는 방법이다. 특정한 함수를 지칭하는 것이 아니라 이 변형 과정 자체를 가리킨다. 예를 들어 process(x, y, z)를 process(x)(y)(z) 바꾸는 과정이 커링이다.
Currying in JavaScript - Kevin Ennis - Medium 에 구현된 자바스크립트 커링 코드를 보면서 원리를 확인해보자.
번역 참고: JavaScript에서 커링 currying 함수 작성하기 | 매일 성장하기 - 김용균
// 커링을 시도할 함수
// 부피를 구하기 위해 길이, 높이, 너비를 인자로 받아 모두 곱한 값을 리턴
function volume(l, w, h) {
return l * w * h;
}
// 주어진 함수를 커링하는 함수
function curry(fn) {
// 주어진 함수가 필요로 하는 전체 인자 길이를 저장해 둔다
const arity = fn.length;
// resolver라는 이름의 IIFE를 구성
return (function resolver() {
// 함수가 전달받은 모든 인자를 배열로 저장한다
const memory = Array.prototype.slice.call(arguments);
// resolver 함수는 다음의 익명 함수를 리턴한다
return function () {
// memory는 이전 프로세스에 저장된 인자들의 배열이다
// 이것의 복사본을 만든다
const local = memory.slice();
// 커링으로 하나씩 들어오는 새 인자를 local 배열에 추가한다
// apply로 받기 때문에 어느 시점에서 나머지 인자를 한꺼번에 부여해도 실행된다
Array.prototype.push.apply(local, arguments);
// next에 무엇을 할당할지는 필요로 하는 모든 인자를 모았는지에 따라 결정된다
// local의 길이가 arity의 길이와 같아지면 모든 인자를 모았다고 보고 fn을 할당
// 그렇지 않으면 아직 모아야 할 인자가 있다는 뜻이므로 resolver를 할당
const next = local.length >= arity ? fn : resolver;
// next에 할당된 함수를 this를 제공하지 않고 인자들만 제공해 실행한다
// fn이 실행되면 결과값이 출력될 것이고, resolver가 실행되면 익명함수 자체가 리턴된다
return next.apply(null, local);
};
})();
}
const curried = curry(volume);
const addLength = curried(10);
const addWidth = addLength(3);
const result = addWidth(7);
console.log(result); // 210커링 또한 지연 실행을 위한 강력한 무기가 된다. 함수의 최종 결과를 한 시점에 받는 것이 아니라 필요한 인자가 확보될 때마다 함수에게 인자를 넘겨줌으로써 연산을 원하는 시점까지 미룰 수 있다.
부분 적용
부분 적용은 커링과 거의 똑같은 개념으로 오해를 받곤 한다. 하지만 약간의 차이가 있는데, 부분 적용은 인수가 여러 개인 함수에서 일부분의 인자를 ‘부분 적용’해서 나머지 인수를 받도록 하는 함수를 도출하는 것이다. 즉 process(x, y, z)에서 x만을 적용해 process(y, z)를 전달받는 것을 말한다.
위에서 적용한 curry 함수는 커링과 부분 적용이 모두 구현된다.
const curried = curry(volume);
const curryResult = curried(10)(7)(3); // 커링
const partial1 = curried(10);
const partialResult = partial1(7, 3); // 부분 적용Ramda.js로 적용하기
위에 나열한 기초 개념을 모두 받아들여서 직접 고계함수를 작성해 운영해도 좋은 경험이 될 것이다. 하지만 미리 만들어진 고성능 라이브러리를 사용하는 것도 좋다. 오늘 소개할 Ramda.js는 순수 자바스크립트만으로 구현된 함수형 프로그래밍 라이브러리이다. 제공되는 모든 함수가 커링과 부분 적용을 지원한다.
자주 사용되는 함수 일부분만 소개하도록 하겠다.
PropOr
고객 정보가 담긴 객체가 있고, 거기서 특정 정보를 꺼내 사용한다고 가정해보자.
import * as R from 'ramda';
const profile = {
name: '홍길동',
amount: 100000,
};
const profileName = R.propOr('이름 없음', 'name');
const profileBank = R.propOr('은행 없음', 'bank');
profileName(profile); // '홍길동'
profileBank(profile); // '은행 없음'propOr 함수는 매개변수로 주어지는 객체에서 지정한 프로퍼티에 해당하는 값을 리턴한다. 만일 원하는 프로퍼티를 찾는데 실패하면 미리 지정해 둔 기본값을 출력한다. 이것은 사이드 이펙트를 관리하기 위한 함수형 프로그래밍의 주요 전략이다. 로직을 기획할 때 데이터의 불완전성에 대비해 유효성 체크를 일일이 설정하는 것이 아니라 입력값의 형태에 따라 출력을 담당하는 함수를 변경하는 것이다. 여기에 ‘카테고리’와 ‘펑터(Functor)’ 개념이 등장하는데 다음의 블로그에 훌륭한 설명이 담겨 있다.
(참고: 어떻게 하면 안전하게 함수를 합성할 수 있을까? - Evan’s Tech Blog)
cond
여러 if문이 중첩될 수 있는 상황을 가정해보자. 기업의 신용 등급에 따라 출력하는 메시지가 달라져야 하는 상황이다.
import * as R from 'ramda';
const getCreditMessage = R.cond([
[R.equals('A'), R.always('상환 능력이 매우 우수함')],
[R.equals('B'), R.always('상환 능력이 보통임')],
[R.equals('C'), R.always('상환 능력이 떨어짐')],
[R.T, R.always('신용 등급 산출되지 않음')],
]);
const companyA = {
grade: 'A',
};
const companyB = {
grade: 'B',
};
const companyC = {
grade: '',
};
getCreditMessage(companyA.grade); // input 값이 A와 일치하면 조건문 배열 두 번째로 넣은 함수의 리턴 값을 반환한다: '상환 능력이 매우 우수함'
getCreditMessage(companyB.grade); // 상환 능력이 보통임
getCreditMessage(companyC.grade);
// 상위 조건문 배열에서 일치하는 값을 찾지 못하면
// default 성격으로 마지막에 배치해 둔 값을 반환한다: '신용 등급 산출되지 않음'cond 함수는 중첩되는 조건과 원하는 결과값을 배열 구조로 전달받아 데이터를 처리하는 함수다. 개발자가 직접 상태를 다루며 분기 처리를 하는 게 아니라 조건과 결과까지 인자로 넘겨 로직을 원자화하고 결과 처리를 고계함수로 양도하는 것이다.
기업재무데이터 더미에서 바늘 같은 데이터 끄집어내기
실제 재무데이터 구조를 모두 밝힐 수는 없지만, 규모가 매우 방대하며 데이터의 key-value가 가독성 있는 문자로 설정되어 있지도 않다. 예를 들면 ‘영업 이익’이라는 항목이라고 해서 ‘profit’ 이라는 키를 갖는 게 아니라 ‘A003020310’ 같은, 키마저 코드화된 채로 담겨 있는 모습을 볼 수 있다. 거기다 재무 데이터는 최신 년도 값만 추출하지 않고 3년 내지 5년 간의 변화를 모두 쿼리한 뒤 그래프로 표현하는 경우가 많다. 먼저 자료 구조부터 체크해보도록 하자.
const companyFinancialData = [
{
date: '2018',
A12435322: 2400000,
B49334893: 13440000,
C34294929: 5500000,
// ...
// 이런 식의 코드화된 데이터가 한 객체에 300개 이상 달려 있다고 가정하자
},
{
date: '2017',
A12435322: 1200000,
B49334893: 10040000,
C34294929: 3300000,
// ...
},
{
date: '2016',
A12435322: 900000,
B49334893: 9040000,
C34294929: 1300000,
// ...
},
];어떤 기업의 3개년 치 재무 데이터가 객체를 요소로 하는 배열 형태로 제공된다고 하자. 여기서 ‘귀속년도’, ‘영업 이익’ 만을 추출해서 새로운 배열을 만들고, 최신 년도가 맨 뒤로 가도록 정렬한다고 가정하자. 어떻게 하면 좋을까?
먼저 순수 자바스크립트 함수들만을 이용해 데이터를 추출해보자.
const result = companyFinancialData
.map(item => ({
date: item.date,
B49334893: item.B49334893, // 'B49334893'를 영업이익 항목이라 가정하자
}))
.sort((a, b) => parseInt(a.date, 10) - parseInt(b.date, 10));
console.log(result);
/*
* [
* { date: '2016', B49334893: 9040000 },
* { date: '2017', B49334893: 10040000 },
* { date: '2018', B49334893: 13440000 }
* ]
*/순수 자바스크립트 함수만을 이용해 체인을 구성할 땐 주의해야 할 점이 있다. 함수가 원본 배열을 변형시키는지, 아니면 새로운 배열을 복사하는지를 확인해야만 한다. map 함수는 리턴 값으로 새로운 배열을 복사하지만 sort 함수는 원본 배열을 변형시킨다. 지금 같은 경우, map 함수를 우선 배치하면서 체인을 시작했으므로 우리가 원하는 결과값 배열은 result 변수 안에 새로운 배열로 담기고, 기존 companyFinancialData 와는 무관해진다. 그러면 sort 함수가 원본 배열을 변형시킨다 해도 result 배열이 변형되는 것이기에 companyFinancialData의 무결성은 지켜진다.
만일 map 함수와 sort 함수의 순서를 바꿔서 체인을 구성한다면 어떻게 될까? sort 함수의 결과값이 result에 담기기는 해서 최종적인 결과값은 동일하게 출력되겠지만 companyFinancialData 또한 정렬되었을 것이다. 원본 배열이 각 요소마다 몇백 개가 넘는 항목이 달린 상태라고 가정한다면 원본 배열이 손상되는 문제와 더불어 메모리에도 악영향을 끼치게 되었을 것이다. map을 먼저 써서 사용자가 원하는 요소만 추출한 뒤, 작아진 배열을 정렬하는 것이 훨씬 효율적인 설계다.
Ramda.js를 사용하면 project라는 함수를 쓸 수 있다.
import * as R from 'ramda';
const getData = R.project(['date', 'B49334893'], companyFinancialData);
const result = R.sort(
(a, b) => parseInt(a.date, 10) - parseInt(b.date, 10),
getData,
);project 함수는 사용자가 추출하기 원하는 객체 키를 문자열 형태로 배열에 넣어 파라미터로 제공하면 거기에 맞춘 배열을 리턴해준다. 이 함수의 장점은, 만일 원본 데이터가 무결하지 않아 사용자가 찾으려는 데이터 일부가 누락되어 있어도 오류를 반환하지 않고 데이터가 누락된 결과물을 그대로 리턴해준다는 것이다. 체이닝이 이루어지는 중에는 에러가 발생하지 않으므로 사용자는 체이닝이 다 끝난 결과물에 대해서만 핸들링을 해 주면 된다. Ramda.js가 제공하는 sort 함수는 당연하게도 원본 배열을 손상시키지 않고 정렬을 돕는다.
Ramda.js의 장점은 모든 함수가 커링과 부분 적용을 자유자재로 제공한다는 것이다. 그것이 가능케 하기 위해 모든 함수는 데이터를 받는 파라미터 위치가 가장 마지막에 놓여 있다. 이러면 로직을 설계하기 위한 함수만 미리 작성해 함수를 변수화 시켜놓고 나중에 데이터를 제공해 지연 실행을 가능케 할 수 있으며, 하나의 함수를 여러 데이터에 재사용하기도 쉽다.
import * as R from 'ramda';
const getProfitData = R.project(['date', 'B49334893']);
const sortByYear = R.sort(
(a, b) => parseInt(a.date, 10) - parseInt(b.date, 10),
);
const result = R.pipe(getProfitData, sortByYear)(companyFinancialData);pipe 함수는 제공된 데이터를 매개변수로 받을 헬퍼 함수의 체인을 만들어주는 함수다. ‘데이터 추출’ -> ‘연도에 따른 정렬’ 이라는 비즈니스 로직을 커링 함수로 각각 구현한 뒤 pipe 함수에 순서대로 넣고, 마지막으로 원본 데이터를 제공하기만 하면 원하는 결과값을 얻을 수 있다. 얼마든지 많은 함수를 넣어도 상관이 없고, 각 함수의 역할 또한 가독성 있게 읽어들이는 것이 가능하다. 이러한 체이닝 방식은 로직이 거듭될수록 더 깊은 depth로 빠져버리는 잘못된 설계를 방지해주고 로직의 유지보수와 확장을 편리하게 만들어준다.
계속해서 새로운 배열을 복사하는 방법, 괜찮을까?
함수형 프로그래밍은 함수 실행이 빚을지 모를 부수효과를 방지하기 위해 원본 데이터를 무결하게 유지하기를 꾀한다. 이를 위해선 데이터를 가공할 때마다 데이터를 새롭게 복사해야만 한다. 하지만 데이터가 크고 로직이 길어질수록 복사 방법은 메모리의 부하를 가져올 것이다. 이 부담을 최소화할 순 없을까? 여기서 나온 개념이 ‘영속 데이터 구조(Persistent data structures)‘이다. 여기에서 전부 설명할 내용은 아니지만, 간단히 요약하자면 원본 데이터를 일종의 해시 트리 구조로 보유한 뒤, 데이터의 가공이 일어날 때마다 가공이 일어난 leaf만을 새로 가공된 데이터로 교체하고 나머지 트리는 그대로 유지하는 방법을 말한다. 자바스크립트에서 이를 구현한 패키지가 바로 immutable.js이다. 페이스북이 개발한 바로 그것… immutable.js가 어떻게 영속 데이터 구조를 구현했고 얼마나 퍼포먼스 향상이 있는지는 이 포스트를 참고하면 좋다.
참고: Immutable.js, persistent data structures and structural sharing
참고
기존의 사고 방식을 깨부수는 함수형 사고 - Evan’s Tech Blog
함수형 프로그래머가 되고 싶다고? (Part 1) · FEDevelopers/tech.description Wiki
JavaScript로 함수형 프로그래밍 배우기 - Anjana Vakil - JSUnconf